Proxy
The Athens Proxy
The Athens proxy has two primary use cases:
- Internal deployments
- Public mirror deployments
This document details features of the Athens proxy that you can use to achieve either use case.
The Role of the Athens proxy
We intend proxies to be deployed primarily inside of enterprises to:
- Host private modules
- Exclude access to public modules
- Store public modules
Importantly, a proxy is not intended to be a complete mirror of an upstream proxy. For public modules, its role is to store the modules locally and provide access control.
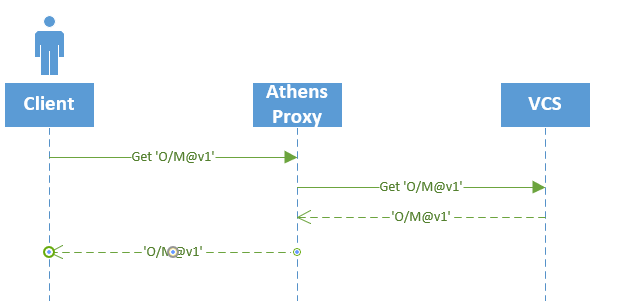
What happens when a public module is not stored?
When a user requests a module MxV1 from a proxy and the Athens proxy doesn’t have MxV1 in its store, it first determines whether MxV1 is private or not private.
If it’s private, it immediately stores the module into the proxy storage from the internal VCS.
If it’s not private, the Athens proxy consults its exclude list for non-private modules (see below). If MxV1 is on the exclude list, the Athens proxy returns 404 and does nothing else. If MxV1 is not on the exclude list, the Athens proxy executes the following algorithm:
upstreamDetails := lookUpstream(MxV1)
if upstreamDetails == nil {
return 404 // if the upstream doesn't have the thing, just bail out
}
return upstreamDetails.baseURL
The important part of this algorithm is lookUpstream. That function queries an endpoint on the upstream proxy that either:
- Returns 404 if it doesn’t have
MxV1 in its storage
- Returns the base URL for MxV1 if it has
MxV1 in its storage
In a later version of the project, we may implement an event stream on proxies that any other proxy can subscribe to and listen for deletions/deprecations on modules that it cares about
Exclude Lists and Private Module Filters
To accommodate private (i.e. enterprise) deployments, the Athens proxy maintains two important access control mechanisms:
- Private module filters
- Exclude lists for public modules
Private Module Filters
Private module filters are string globs that tell the Athens proxy what is a private module. For example, the string github.internal.com/** tells the Athens proxy:
- To never make requests to the public internet (i.e. to upstream proxies) regarding this module
- To download module code (in its store mechanism) from the VCS at
github.internal.com
Exclude Lists for Public Modules
Exclude lists for public modules are also globs that tell the Athens proxy what modules it should never download from any upstream proxy. For example, the string github.com/arschles/** tells the Athens proxy to always return 404 Not Found to clients.
Catalog Endpoint
The proxy provides a /catalog service endpoint to fetch all the modules and their versions contained in the local storage. The endpoint accepts a continuation token and a page size parameter in order to provide paginated results.
A query is of the form
https://proxyurl/catalog?token=foo&pagesize=47
Where token is an optional continuation token and pagesize is the desired size of the returned page.
The token parameter is not required for the first call and it’s needed for handling paginated results.
The result is a json with the following structure:
{"modules": [{"module":"github.com/athens-artifacts/no-tags","version":"v1.0.0"}],
"next":""}'
If a next token is not returned, then it means that no more pages are available. The default page size is 1000.
From VCS to the User
You read about proxy, communication and then opened a codebase and thought to yourself: This is not as simple as described in the docs.
Athens has a set of architectural components that handle Go modules from their journey from the VCS into storage and down to the user. If you feel lost on how all these pieces work, read on my friend!
From communication, you know that when a module is not backed up in the storage it gets downloaded from VCS (such as github.com) and then it is served to the user. You also know that this whole process is synchronous. But when you read a code you see module fetchers and download protocol stashers and you struggle to figure out what’s what and how they differ. It might seem complicated, but this document will help explain everything that’s going on.
Components
Let’s start with describing all the components you will see along the way. There’s no better way to get a clear picture of everything than with a diagram.
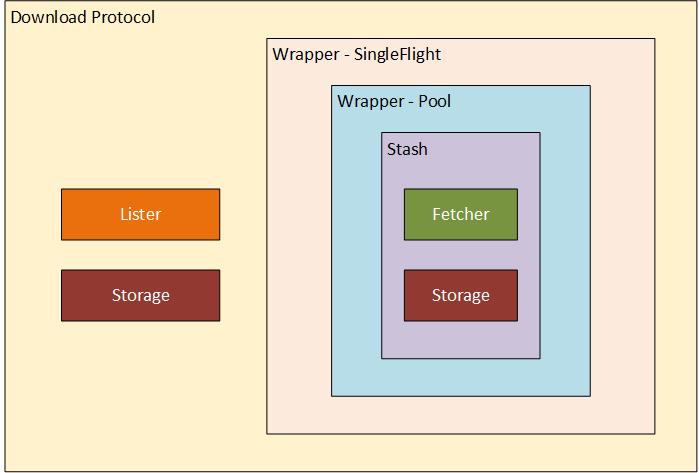
As you can see, there are a lot of layers and wrappers. The first two pieces you’ll see in the code are the Storage and the Fetcher. We’ll start our journey there.
Storage
Storage is what it sounds like. Storage instance created in proxy/storage.go’s GetStorage function.
Based on storage type passed as an ENV variable it will create in-memory, filesystem, mongo… storage.
This is where modules live. Once there, always there.
Fetcher
Fetcher is the first component on our way. As we can guess from the name, Fetcher (pkg/module/fetcher.go) is responsible for fetching the sources from VCS.
For this, it needs two things: the go binary and afero.FileSystem. Path to binary and filesystems are passed to Fetcher during initialization.
mf, err := module.NewGoGetFetcher(goBin, fs)
if err != nil {
return err
}
app_proxy.go
When a request for a new module comes, the Fetch function is invoked.
Fetch(ctx context.Context, mod, ver string) (*storage.Version, error)
fetch function
Then the Fetcher:
- creates a temp directory using an injected
FileSystem
- in this temp dir, it constructs dummy go project consisting of simple
main.go and go.mod so the go CLI can be used.
- invokes
go mod download -json {module}
This command downloads the module into the storage. Once the download is completed,
- the
Fetch function reads the module bits from storage and returns them to the caller.
- The exact path of module files is returned by
go mod as part of JSON response.
Stash
As it is important for us to keep components small and readable, we did not want to bloat Fetcher with storing functionality. For storing modules into a storage we use Stasher. This is the single responsibility of a simple Stasher.
We think it’s important to keep components small and orthogonal, so the Fetcher and the storage.Backend don’t interact. Instead, the Stasher composes them together and orchestrates the process of fetching code and then storing it.
The New method accepts the Fetcher and the storage.Backend with a set of wrappers (explained later).
New(f module.Fetcher, s storage.Backend, wrappers ...Wrapper) Stasher
stasher.go
The code in pkg/stash/stasher.go isn’t complex, but it’s important:
I think this does two things:
- invokes
Fetcher to get module bits
- stores the bits using a
storage
If you read carefully you noticed wrappers passed into a basic Stasher implementation.
These wrappers add more advanced logic and help to keep components clean.
The new method then returns a Stasher which is a result of wrapping basic Stasher with wrappers.
for _, w := range wrappers {
st = w(st)
}
stasher.go
Stash wrapper - Pool
As downloading a module is resource heavy (memory) operation, Pool (pkg/stash/with_pool.go) helps us to control simultaneous downloads.
It uses N-worker pattern which spins up the specified number of workers which then waits for a job to complete. Once they complete their job, they return the result and are ready for the next one.
A job, in this case, is a call to Stash function on a backing Stasher.
Stash wrapper - SingleFlight
We know that module fetching is a resource-heavy operation and we just put a limit on a number of parallel downloads. To help us save more resources we wanted to avoid processing the same module multiple times.
SingleFlight wrapper (pkg/stash/with_singleflight.go) takes care of that.
Internally it keeps track of currently running downloads using a map.
If a job arrives and map[moduleVersion] is empty, it initiates it with a callback channel and invokes a job on a backing Stasher.
s.subs[mv] = []chan error{subCh}
go s.process(ctx, mod, ver)
if there is an entry for the requested module, SingleFlight will subscribe for a result
s.subs[mv] = append(s.subs[mv], subCh)
and once the job is complete, the module is served one level up to the download protocol (or to wrapping stasher possibly)
Download protocol
The outer most level is the download protocol.
dpOpts := &download.Opts{
Storage: s,
Stasher: st,
Lister: lister,
}
dp := download.New(dpOpts, addons.WithPool(protocolWorkers))
It contains two components we already mentioned: Storage, Stasher
and one more additional: Lister.
Lister is used in List and Latest funcs to look upstream for the list of versions available.
Storage is here again. We saw it in a Stasher before, used for saving.
In Download protocol it is used to check whether or not the module is already present. If it is, it is served directly from storage.
Otherwise, Download protocol uses Stasher to download module, store it into a storage and then it serves it back to the user.
You can also see addons.WithPool in a code snippet above. This addon is something similar to Stash wrapper - Pool. It controls the number of concurrent requests proxy can handle.